

Após o artigo “Fraude? A impossível matemática da eleição de São Paulo! (que pode ser lido através deste link), respondi diversos comentários e perguntas acerca do estudo, contudo, a principal reinvindicação foi relativa à aplicação da Lei de Benford aos resultados.
A Lei de Benford ou Lei do Primeiro Dígito Significativo, foi publicada no American Philosophical Society em 1938, por Frank Benford, sob o título “The Law of Anomalous Numbers” (https://www.jstor.org/stable/984802?seq=1) e é utilizada, por exemplo, pela Receita Federal como indicador de fraude fiscal. Nos EUA, evidências baseadas na Lei de Benford já foram admitidas em casos criminais e no Irã, em 2009, foi invocada como evidência de fraude nas eleições. Por mais que não seja fã, segue abaixo a definição da wikipédia:
“A Lei de Benford, refere-se à distribuição de dígitos em várias fontes de casos reais. Ao contrário da homogeneidade esperada, a lei afirma que em muitas coleções de números que ocorrem naturalmente, o primeiro dígito significativo provavelmente será pequeno. Sem homogeneidade, esta distribuição mostra que o dígito 1 tem 30% de chance de aparecer em um conjunto de dados estatísticos enquanto valores maiores tem menos possibilidade de aparecer.
Frank Benford demonstrou que esse resultado se aplica a uma ampla variedade de conjuntos de dados, incluindo contas de eletricidade, endereços, preços de ações, preços de casas, números de população, taxas de mortalidade, comprimentos de rios, constantes físicas e matemáticas. pelas leis de potência (que são muito comuns na natureza).”
Enfim, Benford conseguiu determinar que para uma distribuição de dados, os primeiros dígitos devem aparecer próximo as seguintes proporções:
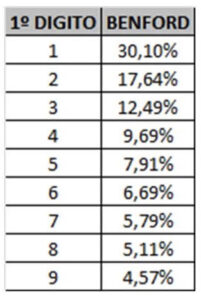
A maior dificuldade para aplicar a Lei de Benford nas eleições, é a obtenção dos dados no site do TSE (www.tse.jus.br). Em cada ano, a cada eleição, a forma de disponibilizar os dados muda no site, e a única forma de realizar a coleta é fazendo um trabalho repetitivo de cópia e cola dos resultados, com posterior tabulação dos dados para análise. Muito trabalho! Para tanto, utilizei os dados do total de votos por zona eleitoral, conforme diversas sugestões que recebi. E para fins de comparação, utilizei os dados das eleições de São Paulo para Prefeito em 2000 (1º turno), para Governador em 2002, também primeiro turno, e o primeiro turno do pleito atual.
E como comparar essas 3 eleições com o preconizado pela Lei de Benford? Bom, montei um gráfico de barras com essas 4 distribuições (SP2000, SP2002, SP2020 e Benford) e busquei encontrar a linha de tendência (o modelo matemático) que melhor representasse os dados, o que é caracterizado por meio do Coeficiente de Regressão Múltiplo (R²) onde, quanto mais perto de 1 o coeficiente, mais bem ajustado está o modelo com os dados utilizados.
Partindo desta premissa, iniciei pela distribuição proposta por Benford e testei até encontrar o modelo matemático que melhor representaria os dados, que no caso foi o da equação de potência, que pode ser representando pela função y = axb, onde o R² encontrado foi de 0,9984. Ou seja, para a distribuição de Benford, o modelo de potência se aproxima muito da unidade, ficando quase que perfeitamente alinhado à linha de tendência e os dados utilizados.
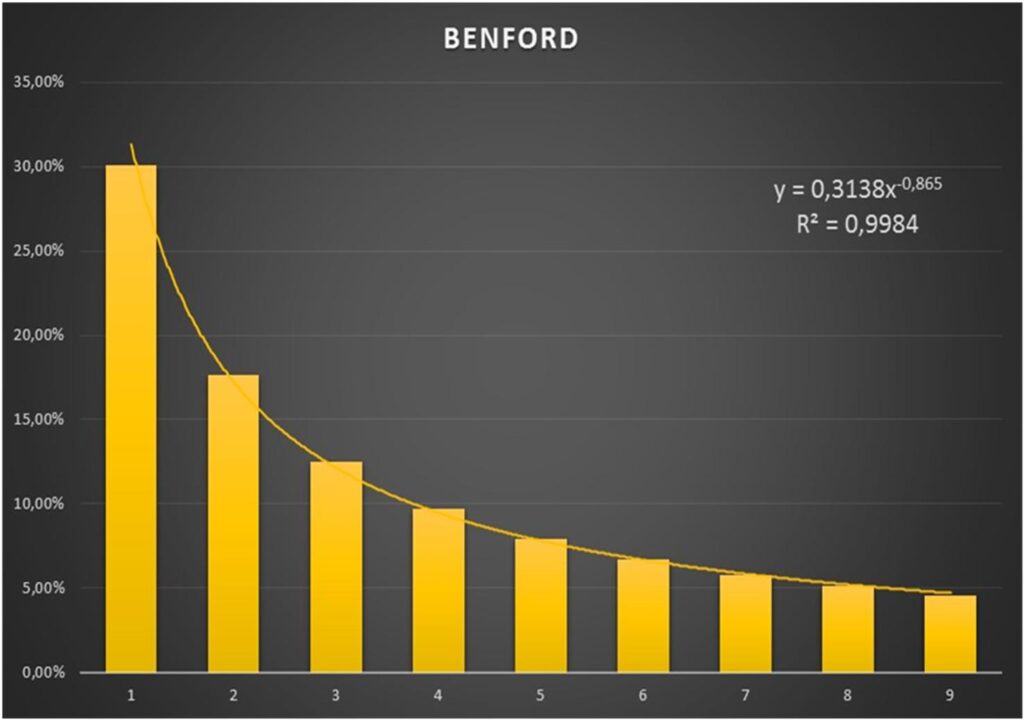
A partir daí encontrei o mesmo modelo de potência (y = axb) com seus respectivos coeficientes R² para cada uma das 3 eleições. Pela lógica, quanto mais distante do coeficiente R² da Lei de Benford, mais distante estaria o resultado da eleição da distribuição dos dados proposta na Lei. Cabe aqui ressaltar que não criei qualquer expectativa que os coeficientes de regressão das eleições fossem iguais ao da Lei, pelo contrário, tinha plena consciência que haveria alguma variação que seria aceitável, por isso fazer a análise com mais de uma eleição.
Seguem abaixo os gráficos de barra com as respectivas linhas de tendência, algoritmos e coeficientes de regressão múltiplo R²:
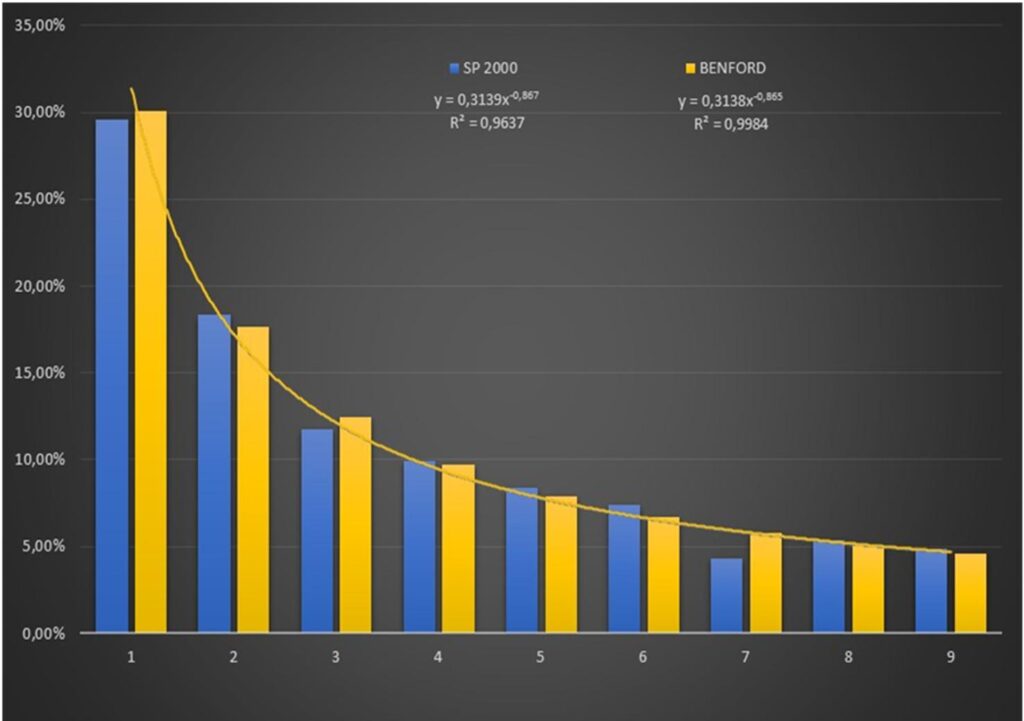
Observa-se que a linha de tendência para o primeiro turno da eleição SP2000, praticamente se sobrepõem a linha de tendência da Lei, o que pode ser confirmado pela proximidade dos Coeficientes de Regressão Multiplo R², sendo o R² SP2000 = 0,9637 e o R² da Lei de 0,9984.

Para a eleição SP2002 a situação se repete, onde as linhas de tendência se encontram praticamente sobrepostas, podendo também ser confirmada pela proximidade do Coeficiente de Regressão Múltiplo R² (R² SP2002 = 0,9699 e R² Benford = 0,9984).
Pensei, estou no caminho certo! Os dados dessas eleições de São Paulo se aproximam do preconizado pela Lei de Benford. Mas quando fui fazer o mesmo processo para eleição de 2020…
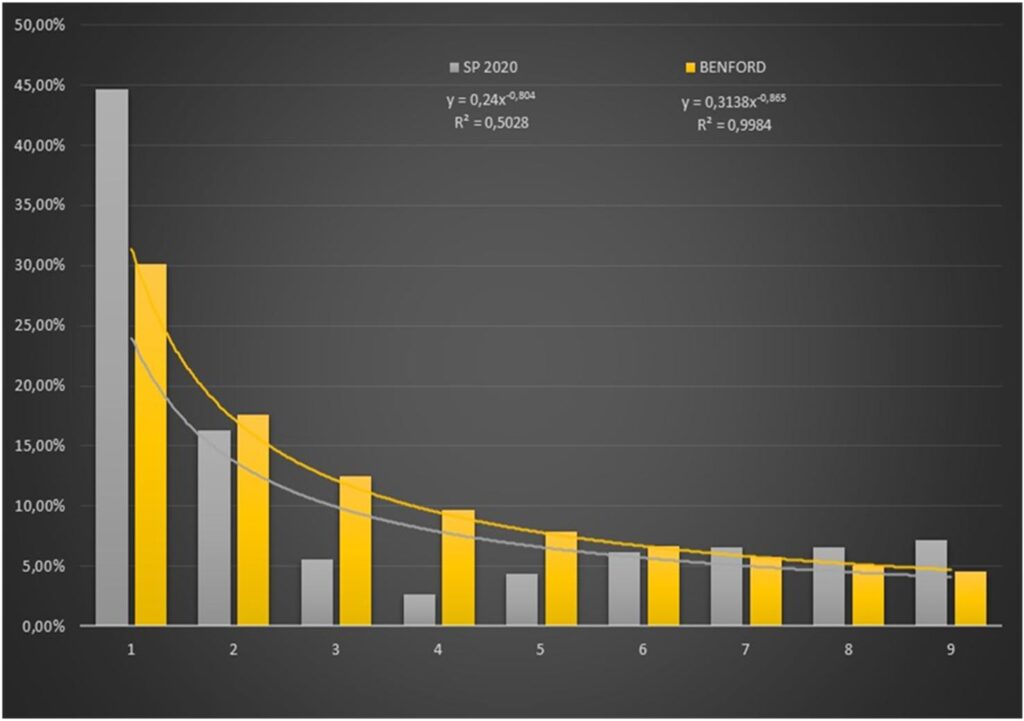
Observa como a frequência de distribuição dos primeiros dígitos se afastam do preconizado pela Lei, o que resulta no afastamento da linha de tendência e se confirma pelo Coeficiente de Regressão Múltiplo, onde o R² de SP2020 foi de somente 0,5028.
Desta forma, posso afirmar que dos 9 pontos analisados para SP2000, SP2002 e Lei de Benford, ao menos 8 estariam perfeitamente alinhados com o modelo, ficando 1 ponto um pouco fora. Já para eleição de SP2020, desses mesmos 9 pontos, somente 4 ou 5 estariam alinhados ou poderiam ser representados pelo modelo, estando os demais fora do alinhamento.
Considerando que o coeficiente de regressão múltiplo R² varia de 0 a 1, e que a nossa referência é o R² encontrado para a distribuição de frequência de Benford, ainda posso inferir, por meio da razão entre o R² das eleições e o da Lei, que SP2000 possui 96,52% de semelhança com o proposto pela Lei, que SP2002 se assemelha a 97,15% com a Lei e que SP2020 possui semelhança de somente 50,36% com a Lei.
Enfim, aparentemente, não houve uma diferença que considere significativa entre as eleições de 2000 e 2002 com Lei de Benford, o que denota que os dados possuem a distribuição esperada. Contudo, posso afirmar que o primeiro turno da eleição para prefeito de São Paulo em 2020 foi um tanto quanto diferente, ou ao menos, com uma distribuição bem mais homogênea que as eleições de SP2000 e SP2002 e que o proposto por Benford. Então houve fraude? Não posso afirmar, mas que, diante de tantas “coincidências” e “probabilidades” tão improváveis, uma investigação se torna premente, pelo bem e segurança da nossa democracia.
Por fim ficam as seguintes perguntas: Homogeneidade numa eleição? Não existem mais os currais eleitorais em São Paulo? Homogeneidade em dados socioeconômicos na maior cidade da América Latina? De maior diversidade cultural de um país continental? Deixo as respostas e conclusões para vocês!
Borges, para Vida Destra, 09/12/2020.
Sigam-me no Twitter! Estou à disposição para comentar e repercutir os dados apresentados! @ABorges78
As opiniões expressas nesse artigo são de responsabilidade de seus respectivos autores e não expressam necessariamente a opinião do Vida Destra. Para entrar em contato, envie um e-mail ao [email protected]
- As Queimadas, os Biomas e suas “Girafas”! - 28 de maio de 2021
- A Pandemia em Números - 19 de janeiro de 2021
- Capitalismo X Pobreza - 5 de janeiro de 2021



{kind=link}
Excelente levantamento! Parabéns!
Excelente a parte II
Vamos esperar a decisão dos órgãos federais para tomarem as devidas providências, tá na cara houve fraude e não só em sp, em td o país ??????
Justamente @Aborges78 não existem mais currais eleitorais em SP, porque Boulos assegurando maioria no Itaim, região de classe rica, não foi com os filhinhos universitários dos proprietários, mas com bugs para influenciar as estatísticas. Acorda povo paulista!
Excelente análise e explicação!
Lido e compartilhado!